
こんにちは、リブセンスでデータサイエンティストをしている北原です。今回は以前の記事の続きで転職ドラフトの年収非公開施策のデータ分析について紹介します。階層ベイズを利用した推定を行います。
以前の記事では提示年収のばらつきをユーザー別標準偏差の平均で計算していました。指名数が多いユーザーばかりであればこの方法で十分なのですが、実際には指名数数件のユーザーが大半を占めます。指名数が少ないと正確な標準偏差が得られにくいので、ばらつきの適切な評価がしにくいという問題があります。そこで、階層ベイズを利用して指名数が少ないユーザーの情報を適度に取り込んだ推定を行うことで、ばらつきをより適切に評価しやすくします。
転職ドラフト年収非公開施策のデータ分析については下記の記事もご参照ください。
転職ドラフトの年収非公開施策のデータ分析
まず簡単におさらいです。以前の記事をお読みになられたことがあるのであれば読み飛ばしていただければと思います。
転職ドラフトは競争入札型のユニークなエンジニア向け転職サービスです。面接などの本格的な選考前に企業から年収が提示される仕組みになっています。提示年収は公開されているので、その後に続く企業は他社の提示年収を参考に自社の提示年収を決めることができます。この仕組みはエンジニアの実力が正当に評価されるよう採用市場の透明化を図ったものです。
しかし、過去の提示年収に影響されてその後の提示年収が決まることで、ユーザーあるいは企業にとって不公平になっている可能性があるのではないかという懸念もありました。そこで2020年8月に行われたのが年収を非公開にすることで過去の提示年収に影響されないようにする年収非公開施策です。以前の記事では年収非公開施策の分析結果について紹介しました。今回の記事もこの年収非公開施策の分析に関連したものになっています。
課題
以前の記事で行った分析方法は集計とグラフによる可視化のみを使った分析でした。このように実務のデータ分析では、手間のかかる高度な分析手法を使うことより、仮説構築とクロス集計などの手軽な方法を使った多面的な分析を繰り返すことのほうが多いのではないでしょうか。
しかし、簡単な分析手法だけだと限界があるのも事実です。以前の記事で行った分析の場合でいうと提示年収のばらつきの分析は望ましいやり方とは言えません。
転職ドラフトの指名データには1ユーザーあたりの指名数が少ないという問題があります。提示年収のばらつきの分析ではユーザーごとに計算した提示年収の標準偏差の平均を利用していますが、1ユーザーあたりの指名数が少ないので標準偏差の計算がしにくく扱いが難しいです。
もう少し具体的に考えてみましょう。この分析では指名が2件以上あったユーザーごとに標準偏差を計算しています。ざっと目を通すだけだと見落とすかもしれませんが、少し考えると問題があることがわかると思います。指名が2件しかないユーザーの標準偏差を信用してよいのでしょうか。標準偏差を計算するには少なすぎる気がしますね。ならば3件以上であればよいのでしょうか。しかし2件と3件では大差がないですし、指名2件のユーザーを除外するのも適切ではない気がします。指名が増えれば増えるほどユーザーの標準偏差を正確に推定できるようになりますが、該当ユーザーが少なくなる問題もあります。最近だと各開催回で10件以上の指名があるユーザーは全体の2〜3%程度なので、指名が多いユーザーのみを対象にすると分析に使えるデータがほとんどなくなります。
このような問題があることを踏まえると、なるべくデータを切り捨てず、データ数が少ないときは少ないなりに適切な推定値を計算できる方法を使いたいところです。
そこで、今回は階層ベイズモデルを利用して推定します。適切な事前分布を設定した階層ベイズを使うことで小標本データのパラメータを推定することができます。階層ベイズの考え方やStanでの実装については以下の記事もご参照ください。
モデル
今回知りたいのは各開催回の提示年収のばらつきです。ユーザーの提示年収のばらつきというより、各開催回で提示年収のばらつきがどうなっているかが分析対象です。ついでに各開催回の提示年収水準についても推定します。
では、モデルについて検討しましょう。
各指名の提示年収はユーザーごとの提示年収水準と各開催回の提示年収水準補正の和で表現できると仮定します。ユーザーごとのスキルの違いなどの全ての情報はユーザーごとの提示年収パラメータに含まれ、同一ユーザーであれば提示年収は変わらないという仮定をおいています。つまり、短期的なスキル向上による年収向上効果は含まれていません。今回使うデータは転職ドラフト1月回から9月回までのもので期間が比較的短いので、時間経過による効果は小さいと判断しました。各開催回の盛り上がりや採用市場のマクロな影響などの情報は各開催回の提示年収水準補正に含まれます。また、提示年収同士は独立という仮定もおいています。ユーザー同士は独立と考えても問題なさそうですが隣接開催回同士は相関を考慮したほうがよりよいモデルになると考えられます。しかし、モデルの複雑化を避けるために今回は独立と仮定した簡単なモデルにしています。
各指名のばらつきもユーザーごとの提示年収の標準偏差と各開催回における提示年収の標準偏差補正の和で表現できると仮定します。各開催回における提示年収の標準偏差補正が今回推定したいものです。ユーザーの標準偏差についてもユーザー別にパラメータを設定します。スキルや職務経歴書の書き方がユーザーによって異なるので、実力を評価しやすい人と評価しにくい人がいるためです。実力を評価しやすい人は提示年収のばらつきが小さくなり、逆に評価しにくい人ではばらつきが大きくなると考えられます。また、提示年収水準が高いほど、ばらつきが大きい傾向があり、そのような情報もユーザー別の標準偏差パラメータに含まれます。
ユーザー別のパラメータには事前分布を設定することで階層化し、各開催回のパラメータは無情報事前分布とします。すでに説明したように1ユーザーあたりの指名数は多くないので、事前分布を設定し安定した推定ができるようにします。事前分布はユーザー全体の傾向を表しているというイメージです。一方で、1開催回あたりの指名数は推定がおかしくなるほど少なくはないので、各開催回のパラメータについては特に事前分布を設定していません。
ユーザー別のパラメータの事前分布には平均、標準偏差ともに対数正規分布を仮定します。高額所得者を除くと所得分布は対数正規分布にしたがうことが知られており、提示年収の分布も対数正規分布によくフィットするためです。平均だけでなく、標準偏差の事前分布にも対数正規分布を使っています。提示年収水準が高いユーザーほど提示年収のばらつきも大きい傾向が見られることや、標準偏差についてについても比較的よく対数正規分布にフィットしているためです。
各提示年収は正規分布にしたがうと仮定しています。指名が多いユーザーを抽出して分布を調べても指名数は多くとも数十件程度なので正確な分布形状はわかりにくいのですが、正規分布から大きく外れているケースは少なかったためです。また、本来の実力に見合う年収を中心とした左右非対称な分布にしたがうというのは、的外れな仮定でもないと思われます。
以上を踏まえて、次のモデルを使います。ただし、識別可能性を考慮し、基準となる開催回にはパラメータを設定しません。つまり、基準となる開催回と比較して提示年収の平均が上がったか下がったかを表すモデルになっています。
${\mathcal N}(\mu, \sigma)$は平均$\mu$、標準偏差$\sigma$の正規分布、${\mathcal {LogN}}(\mu, \sigma)$は平均$\mu$、標準偏差$\sigma$の対数正規分布を表します。また、ユーザー数を$N$、開催回数(基準回のパラメータは存在しないので正確には開催回数-1)を$M$、$i$番目のユーザーの$j$回目の開催回での指名数を$K_{i, j}$、とします。変数が表すものは以下の通りです。
| 記号 | 意味 | 値の範囲 |
|---|---|---|
| $x_{i, j, k}$ | $i$番目のユーザーの$j$番目の開催回での$k$番目の提示年収 | 0以上 |
| $\mu^{(u)}_i$ | $i$番目のユーザーの提示年収の平均 | 0以上 |
| $\mu^{(m)}_j$ | $j$番目の開催回の提示年収の平均 | 全て |
| $\sigma^{(u)}_i$ | $i$番目のユーザーの提示年収の標準偏差 | 0以上 |
| $\sigma^{(m)}_j$ | $j$番目の開催回の提示年収の標準偏差 | 0以上 |
| $\mu^{(u)}_{\mu}$ | $\mu^{(u)}_j$の事前分布の平均 | 0以上 |
| $\mu^{(u)}_{\sigma}$ | $\sigma^{(u)}_j$の事前分布の平均 | 0以上 |
| $\sigma^{(u)}_{\mu}$ | $\mu^{(u)}_j$の事前分布の標準偏差 | 0以上 |
| $\sigma^{(u)}_{\sigma}$ | $\sigma^{(u)}_j$の事前分布の標準偏差 | 0以上 |
プレート表現は以下のようになります。
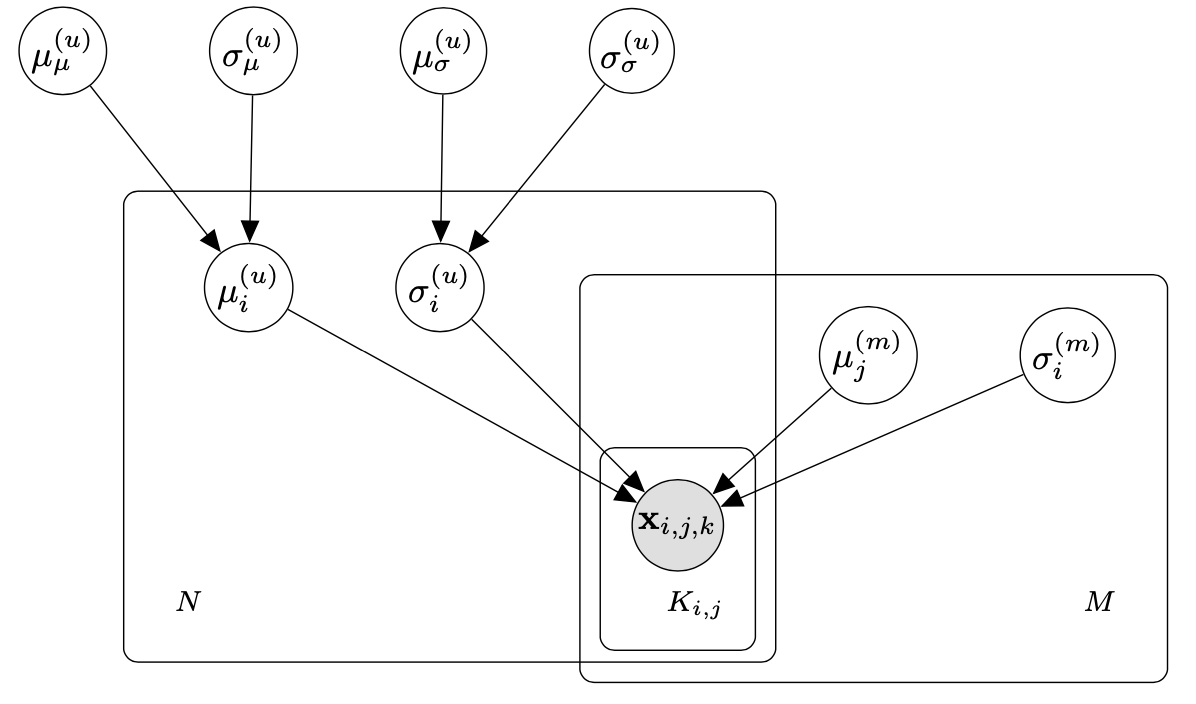
今回推定したいのは各開催回の提示年収の標準偏差$\sigma^{(m)}_k$で、この推定値から年収非公開施策回(8月回)前後でどのぐらいばらつきが増えたかがわかります。また、$\mu^{(m)}_k$は基準回と比較した各開催回の提示年収水準なので、この推定値についても調べます。複数回指名を受けたことのあるユーザーのみに限定されますが、各開催回に平均提示年収の高いあるいは低いユーザーが含まれることで平均提示年収が高くなったり低くなったりするバイアスの影響を緩和することができます。そのため、単純な平均よりも正確な提示年収水準を推定することができます。
このモデルのデメリットは標準偏差が一番小さい開催回を基準にしなければならないところにあります。なぜこのような制限があるかというと、開催回の標準偏差パラメータ$\sigma^{(m)}_k$が負の値をとれないようにしているためです。なぜ$\sigma^{(m)}_k$が負の値をとれないようにしているかというと、正規分布の標準偏差$\sigma^{(u)}_j + \sigma^{(m)}_k$ が非負にならないようにするためです。他によりよい方法があるかもしれませんが、開催回が多いわけではないし標準偏差が一番小さい開催回も検討がつけやすいため、今回はこのモデルを使っています。なお、標準偏差が一番小さい開催回は試行錯誤的に探しました。
推定結果
以前の記事と同じく、転職ドラフトの1月回から9月回までの提示年収データを使います。年収非公開施策は8月回で実施されています。提示年収の平均も計算するため、指名数が少ないユーザーも含め全データを使っています。
モデルパラメータの推定にはStanを利用しています。chainsはデフォルトの4とし、warmup = 2,000、iter = 7,000としているので、1パラメータあたり20,000サンプルになっています。また、adapt_delta = 0.99とmax_treedepth = 15も指定しています。
以前の記事と同様に、希望年収ありのユーザーと希望年収なしのユーザーは個別に分析します。ユーザーは希望年収ありもしくはなしのいずれかなので、希望年収ありのユーザーと希望年収なしのユーザーは個別に推定しています。
開催回パラメータは、基準回を0としたときの差分の値が推定されます。これはユーザー別の提示年収に開催回ごとの差分を加える形のモデルになっているためです。例えば、ある開催回の提示年収平均が10と推定されていた場合、この結果は基準回の提示年収平均と比較してその開催回の提示年収平均は10大きかったということを示しています。基準回は、希望年収ありユーザーでは7月回、希望年収なしユーザーでは5月回が該当します。
今回の目的であった各開催回の提示年収の標準偏差について見ていきましょう。
希望年収ありのユーザーに関する各開催回の提示年収標準偏差のパラメータ分布は以下の通りです。
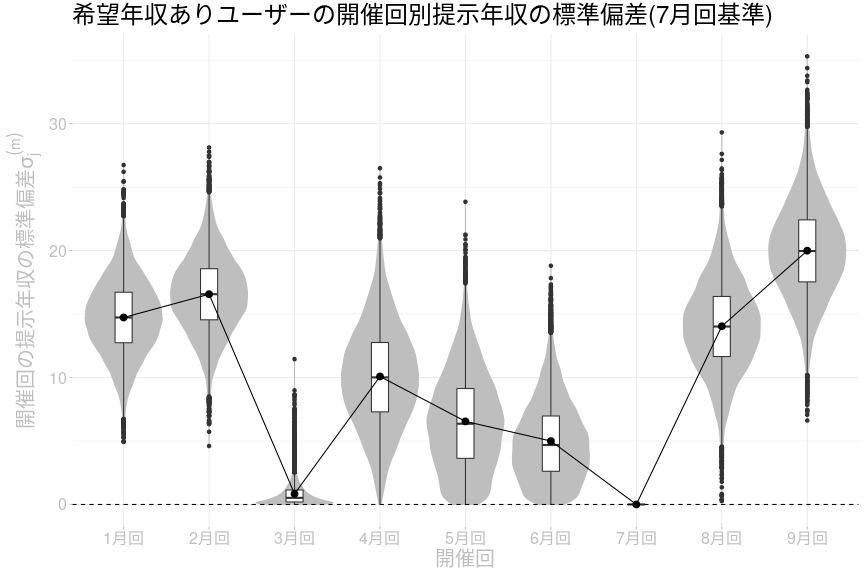
まずグラフについて説明します。分布を表すヴァイオリンプロットに、四分位を表す箱ひげ図を加えています。さらに、分布の平均を黒点で表し、変化をわかりやすくするため平均を線で結んでいます。基準回のパラメータは推定されていないので0とし、基準ラインを明確にするために破線を表示しています。本記事の他の推定結果も同じグラフを使います。
今回の推定結果でも以前の記事で紹介した提示年収のばらつきと同じような傾向が見られることがわかります。年収非公開回である8月回前後の傾向は以前の記事と同じなので、考察や結論についてはそのまま適用できると考えています。1〜2月回と8〜9月回の標準偏差が大きく、3月回と7月回では小さくなっているところは以前と同じです。今回の推定結果では4〜6月回にかけて徐々に小さくなっていますが、以前の記事では5月回のばらつきが4月回や6月回より大きくなっており、このあたりに違いが表れています。9月回の標準偏差が8月回より大きい確率を計算すると90.9%となっているので、誤差を考慮しても8月回と比較して9月回のほうがばらつきが大きくなっている可能性は高いと言えます。
希望年収なしのユーザーに関する各開催回の提示年収標準偏差のパラメータ分布は以下の通りです。
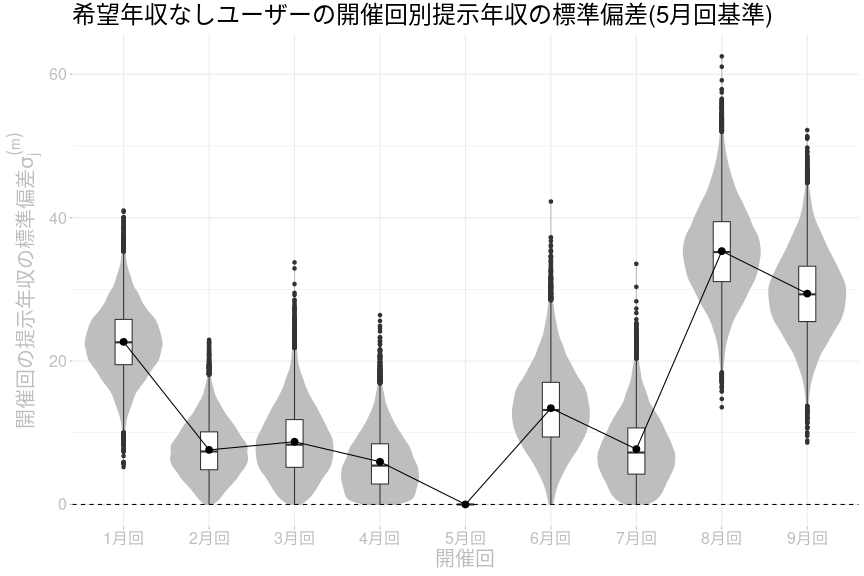
希望年収なしユーザーの標準偏差についても、概ね以前の記事と同じ傾向が得られています。年収非公開回前後の傾向は以前の記事と同じなので、考察や結論についてはそのまま適用できると考えています。8〜9月回は大きく、1月回も大きめ、4〜5月回は小さいというところは以前と同じです。以前は2〜3月回は6月回と同程度に大きかったのですが今回の推定では7月回と同程度になっているところが異なる部分です。8月回の標準偏差が7月回より大きい確率は100%、8月回が9月回より大きい確率は78.8%なので、8月回でばらつきが大きくなったのはほぼ確実で、9月回ではばらつきが縮小した可能性が高いと言えます。
次に、各開催回の提示年収水準について見ていきましょう。
希望年収ありのユーザーに関する各開催回の提示年収水準のパラメータ分布は以下の通りです。
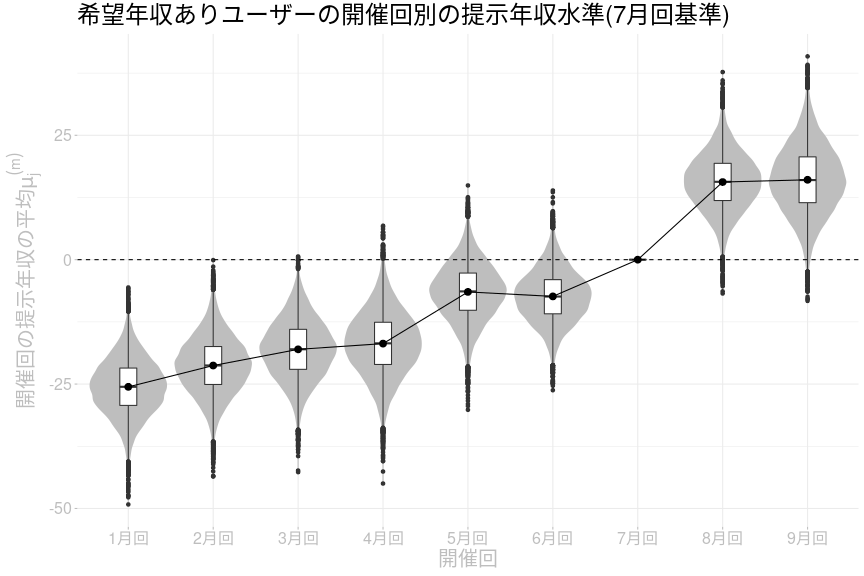
希望年収ありユーザーの提示年収水準についても、概ね以前の記事と同じ傾向が得られています。8〜9月回の提示年収が高いのは以前と同じです。以前の記事とは異なり、1月回や6月回の推定値が低く推定されており、緩やかなトレンドが確認しやすくなっています。8月回が7月回より高い確率は70.7%なので8月回では提示年収水準が上昇した可能性が高いです。一方で、8月回が9月回より高い確率は56.1%とそれほど高くはないので、8月回だけ提示年収水準が高くなっていた可能性は低いです。
希望年収なしのユーザーに関する各開催回の提示年収水準のパラメータ分布は以下の通りです。
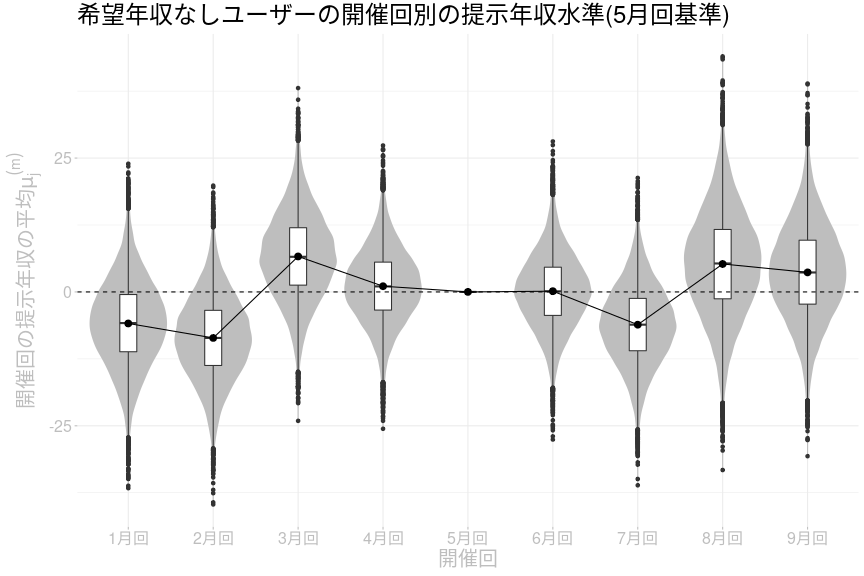
希望年収なしユーザーの提示年収水準についても、概ね以前の記事と同じ傾向が得られています。この推定結果では後半開催月のほうが提示年収水準が高めですが、以前ほど上昇トレンドが明確ではなくなっています。今回の推定結果でも8月回の提示年収水準は前後の月と比較して高いです。8月回が7月回より高い確率は86.8%なので提示年収水準が上昇した可能性が高いのですが、8月回が9月回より高い確率は56.1%とそれほど高くはないので8月回だけ提示年収水準が高くなっていた可能性は低いです。
まとめ
今回は転職ドラフトの提示年収非公開施策の分析で行った提示年収のばらつきの分析を階層ベイズを利用して行いました。ユーザーあたりの指名数が少ないため標準偏差をそのまま計算しただけでは適切な値を推定しにくいですが、階層ベイズを利用することでより適切な推定が可能になりました。今回の推定では以前の記事とは少し異なる結果が得られたものの、結論を変えなければいけないほどの違いはありませんでした。