
データエンジニアリングチームのよしたけです。 弊社各サービスのデータ分析基盤であるLivesense Analyticsの開発、運用を行っています。
Livesense Analyticsのアーキテクチャ
Livesense AnalyticsはAWS上でシステムが構築されています。S3上にあるデータやtd-agent、Kinesis Firehoseなどを経由して集めたデータをAmazon Redshiftに格納し、データウェアハウスとして運用しています。詳細は、弊社大政がデータ分析基盤Night #1 で発表した内容をご参照ください。
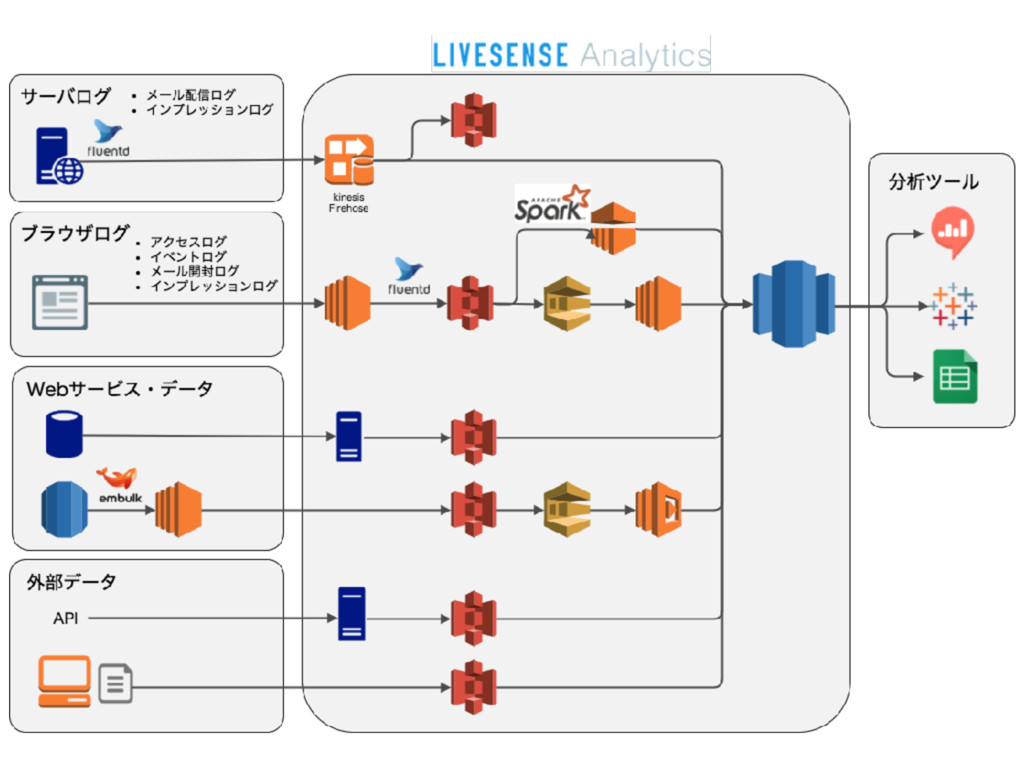
当時とは一部変更になっている部分もありますが、大枠は上記の図の構成になっています。
ディスク使用量
このLivesense Analyticsには、マッハバイトや転職会議をはじめ、リブセンスで運用している多くのメディアの各種ログやデータが集められています。そのため、Redshift上にあるデータは日々増加の一途を辿っており、空き容量の確保や、ヤンチャなクエリがテンポラリテーブルでディスクを食いつぶすのを未然に止める、などの運用に日々追われています。
普段はRedshiftのコンソール画面からディスク空き容量などの監視を行っていますが、具体的にどのテーブルのサイズが増加しているのか、1ヶ月前と比べてどれくらい増加しているのか、といった分析がコンソール画面からは出来ません。
そこで、システムテーブルのSVV_TABLE_INFOのスナップショットを毎日取得するようにしています。このテーブルにはどのスキーマのどのテーブルがどれくらいの容量を使用しているのか、という情報が含まれているため、このデータを1日1回スナップショット格納用テーブルにSELECT INSERTすることでデータを貯めていきます。SVV_TABLE_INFOの持っているカラムの他に、スナップショットを取得した日時カラムも併せて保持しています。
このスナップショットを集めたテーブルを使い、re:dashでグラフ化して毎日のデータ増加量やスキーマごとのデータ量の割合、増加量を監視しています。弊社では、メディア、サービスごとにスキーマを分ける運用をしているため、どのメディアのデータが増加しているのかが分かるようになっています。



encode指定
では実際に使用量を削減していくにはどうしたらいいか、という話をしたいと思います。
Redshiftでテーブルを作成する際に、ENCODE指定を各カラムに行います。
ENCODEで指定できるエンコードタイプには以下の種類があります
| VARCHAR | SMALLINT | INTEGER | BIGINT | DECIMAL | REAL | DOUBLE PRECISION | DATE | TIMESTAMP | BOOLEAN | |
|---|---|---|---|---|---|---|---|---|---|---|
| RAW | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| BYTEDICT | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | × |
| DELTA | × | ○ | ○ | ○ | ○ | × | × | ○ | ○ | × |
| DELTA32K | × | × | ○ | ○ | ○ | × | × | ○ | ○ | × |
| LZO | ○ | ○ | ○ | ○ | ○ | × | × | ○ | ○ | × |
| MOSTLY8 | × | ○ | ○ | ○ | ○ | × | × | × | × | × |
| MOSTLY16 | × | × | ○ | ○ | ○ | × | × | × | × | × |
| MOSTLY32 | × | × | × | ○ | ○ | × | × | × | × | × |
| RUNLENGTH | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| TEXT255 | ○ | × | × | × | × | × | × | × | × | × |
| TEXT32K | ○ | × | × | × | × | × | × | × | × | × |
| ZSTD | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
各エンコードタイプの特徴はAWSのページを参照していただくとして、これらのうち、どのカラムにどのエンコードタイプを選択すればいいのでしょうか?
検証方法として、実際にそれぞれのエンコードタイプのカラムにデータを入れてみて、どれくらいのサイズになるのか確認してみるのがよさそうです。
以下のクエリはINTEGER型の値について、各エンコードタイプ指定がしてあるテーブルを作成し、対象カラムのデータをINSERTしてみる例です。
CREATE TABLE encode_test ( value_raw INTEGER ENCODE RAW, value_bytedict INTEGER ENCODE BYTEDICT, value_delta INTEGER ENCODE DELTA, value_delta32k INTEGER ENCODE DELTA32K, value_lzo INTEGER ENCODE LZO, value_mostly8 INTEGER ENCODE MOSTLY8, value_mostly16 INTEGER ENCODE MOSTLY16, value_runlength INTEGER ENCODE RUNLENGTH, value_zstd INTEGER ENCODE ZSTD );
INSERT INTO encode_test ( value_raw, value_bytedict, value_delta, value_delta32k, value_lzo, value_mostly8, value_mostly16, value_runlength, value_zstd ) SELECT target_value, target_value, target_value, target_value, target_value, target_value, target_value, target_value, target_value FROM src_table;
次にこのテーブルの各カラムがどれくらいディスクを使用しているかを確認します。STV_BLOCKLISTというシステムテーブルから、列ごとにどれくらいのブロックが使用されているかMB単位で取得することが出来ます。
SELECT col, -- 0オリジンで、encode_testテーブルに指定したカラムに対応 MAX(blocknum) FROM stv_blocklist AS b, stv_tbl_perm AS p WHERE b.tbl = p.id AND p.id = ( SELECT table_id FROM svv_table_info WHERE "table" = 'encode_test' ) AND col < 9 -- encode_testテーブルで作成したカラムの数を指定 GROUP BY name, col ORDER BY col;
実際のデータを用いて得られた結果をお見せします。弊社のあるサービスのアクセスログが格納されているテーブルについて、最適なエンコードタイプがどれになるか見てみようと思います。
各カラムについてデータの特性がイメージしてもらえるよう、以下の値を併せて出しています。
- 平均文字列長(varchar型のみ)
- ユニークデータ数
- 値ごとの平均レコード数
- NULL値列
- 値ごとのレコード数の標準偏差
また、各エンコードタイプの圧縮率をまとめています。圧縮率はエンコードタイプrawのディスクサイズとの割合から算出しています。
検証を行った環境は、ノードタイプdc2.large、ノード数18台のRedshiftクラスタを使用しています。対象となるアクセスログテーブルは約3億件のレコードが格納されています。
varchar型カラム
| カラム | 平均文字列長 | ユニークデータ数 | 値ごとの平均レコード数 | NULL値率 | raw | lzo | zstd | bytedict | runlength | text255 | text32k |
|---|---|---|---|---|---|---|---|---|---|---|---|
| access_id | 36.00 | 305260271 | 1.00 | 0.00% | 100.00% | 77.95% | 45.02% | 95.47% | 100.30% | 120.54% | 179.76% |
| session_id | 36.00 | 94677977 | 3.22 | 0.00% | 100.00% | 85.50% | 48.94% | 95.17% | 100.00% | 122.36% | 183.99% |
| user_id | 31.99 | 35762700 | 8.54 | 0.01% | 100.00% | 56.19% | 32.44% | 93.98% | 100.00% | 117.06% | 172.91% |
| ip | 13.99 | 16101001 | 18.96 | 0.00% | 100.00% | 51.35% | 33.11% | 124.32% | 100.68% | 89.86% | 95.27% |
| url | 87.34 | 51500368 | 5.93 | 0.00% | 100.00% | 33.64% | 22.82% | 4091.82% | 100.26% | N/A | 122.30% |
| url_host | 8.04 | 3 | 101,768,565.67 | 0.00% | 100.00% | 0.95% | 0.95% | 8.57% | 0.95% | 77.14% | 139.05% |
| url_path | 14.22 | 5292074 | 57.69 | 0.00% | 100.00% | 41.77% | 29.75% | 1786.71% | 97.47% | N/A | 100.00% |
| user_agent | 130.20 | 471837 | 647.06 | 0.00% | 100.00% | 14.91% | 10.16% | 270.08% | 96.07% | N/A | 93.69% |
| device | 8.41 | 7 | 43,615,099.57 | 0.00% | 100.00% | 8.33% | 3.70% | 8.33% | 25.93% | 15.74% | 30.56% |
| os | 6.98 | 43 | 7,100,132.49 | 0.00% | 100.00% | 17.71% | 9.38% | 9.38% | 68.75% | 20.83% | 39.58% |
| browser | 7.10 | 29 | 10,527,782.66 | 0.00% | 100.00% | 16.33% | 8.16% | 9.18% | 62.24% | 17.35% | 34.69% |
| page_type | 7.57 | 50 | 6,106,113.94 | 0.00% | 100.00% | 25.74% | 13.86% | 8.91% | 88.12% | 28.71% | 54.46% |
上記の結果から、圧倒的にZstandardの圧縮率が高いことがわかります。今年の1月に新しいエンコードタイプとして追加され、それ以前は迷ったときのlzo頼みだったのですが、今やそのポジションは同じような特性を持ちかつ圧縮率のよいZstandardに置き換わったといえます。
一方、osやpage_type(URLによって付けられるページ種類のタグのようなもの)カラムのように、値の種類が限定されるカラムについてはbytedictが有効です。公式ページによると
このエンコードは、列に含まれる一意の値の数が制限されている場合に非常に効果的です。このエンコードは、列のデータドメインが一意の値 256 個未満である場合に最適です。
とのことですが、種類が少ないとあまり効果は出ないようです。50個程度であれば効果が期待できます。また、長い文字列など値のサイズが大きい場合、bytedictは極端に性能が悪化するので注意が必要です。
また特定の値(NULLとか)が殆どの場合は、runlengthが効果を発揮します。公式ページによると
たとえば、大きなディメンションテーブルの列に、予測どおりに小さなドメイン (10 個未満の可能値を持つ COLOR 列など) がある場合、データがソートされなくても、これらの値はテーブル全体にわたって長いシーケンスになる可能性が高くなります。
とありますが、こちらの傾向としては特定の値が99%以上を占めるようなデータの場合に効果が出るようで、deviceのように値の種類が10個未満でも効果が出ない場合があったり、逆に種類が多くても特定の値が99%を占めるようなデータであればrunlengthが効果的な場合もあります。
integer型カラム
| カラム | ユニークデータ数 | 値ごとの平均レコード数 | NULL値率 | raw | lzo | zstd | bytedict | delta | delta32k | mostly8 | mostly16 | runlength |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| access_count | 24422 | 12,501.26 | 0.00% | 100.00% | 45.45% | 24.24% | 27.27% | 27.27% | 51.52% | 30.30% | 54.55% | 109.09% |
| session_count | 6088 | 50,148.77 | 0.00% | 100.00% | 45.45% | 24.24% | 27.27% | 27.27% | 51.52% | 30.30% | 54.55% | 106.06% |
| elapsed_sec | 42663 | 7,156.22 | 0.00% | 100.00% | 57.58% | 39.39% | 66.67% | 81.82% | 51.52% | 69.70% | 54.55% | 112.12% |
| entry_id | 1198370 | 254.77 | 99.33% | 100.00% | 100.00% | 100.00% | 100.00% | 100.00% | 100.00% | 200.00% | 200.00% | 100.00% |
| item_id | 1874261 | 162.89 | 62.79% | 100.00% | 100.00% | 69.23% | 115.38% | 123.08% | 123.08% | 115.38% | 115.38% | 123.08% |
integerについても圧倒的にZstandardの圧縮率が高いことがわかります。
varcharではNULLデータが多いカラムだとrunlengthが効果的でしたが、integerについては1データのサイズがvarchatと比べて小さいためか、entry_idのようにあまり差が出ませんでした。
date型カラム
| カラム | ユニークデータ数 | 値ごとの平均レコード数 | NULL値率 | raw | lzo | zstd | bytedict | delta | delta32k | runlength |
|---|---|---|---|---|---|---|---|---|---|---|
| access_day | 1165 | 262,064.98 | 0.00% | 100.00% | 3.03% | 3.03% | 27.27% | 27.27% | 51.52% | 3.03% |
| session_start_day | 1165 | 262,064.98 | 0.00% | 100.00% | 3.03% | 3.03% | 27.27% | 27.27% | 51.52% | 3.03% |
dateカラムについてはZstandardだけでなく、LZO、runlengthも効果的なことがわかります。値によってデータ数に差があまりなく、同じ値が連続しているため、runlengthでも効果が大きかったのではないかと推測します。
timestamp型カラム
| カラム | ユニークデータ数 | 値ごとの平均レコード数 | NULL値率 | raw | lzo | zstd | bytedict | delta | delta32k | runlength |
|---|---|---|---|---|---|---|---|---|---|---|
| hit_time | 85443858 | 3.57 | 0.00% | 100.00% | 81.54% | 52.31% | 112.31% | 112.31% | 124.62% | 112.31% |
| visit_time | 55451781 | 5.51 | 0.00% | 100.00% | 80.00% | 53.85% | 112.31% | 112.31% | 124.62% | 112.31% |
一方timestampカラムについてはZstandard一択と言えそうです。dateカラムと違い、値がミリ秒単位であるため、runlengthやdeltaの効果が出にくいのかもしれません。
結果
今回の結果を受け、このアクセスログテーブルのエンコードタイプ指定を見直してみました。RedshiftにZstandardが対応される前に作られたテーブルだったため、主にlzoを使っており、まだZstandard導入をしていませんでした。
エンコード指定を見直した結果、テーブルのディスク使用量が76,883MBから50,849MBと約2/3に削減されました。同じ手順で他のテーブルにもエンコードタイプ見直しを進めていくことで、効果的なサイズ削減が実現できそうです。
最後に
Amazon Redshiftの増加していくデータに対してどう向き合っていくかという話をさせていただきました。re:dashを使ってデータ増加を監視しつつ、エンコードタイプを見直してデータ量削減を効果的に行うことが出来ました。特にZstandardの導入が効果的であることが分かりました。
なお今回はデータ量についてフォーカスさせていただきましたので、エンコードタイプによる実行速度の比較は行いませんでした。こちらは別の機会にまとめてみたいと思います。
エンコードタイプ見直しの他にもDISTKEYの見直しやRedshift Spectrumの導入、データ移行など、色々な施策に取り組んでおります。こちらもまた別の機会にご紹介したいと思います。